How to Track Your Brand's 'Share of Voice' in AI Search Results
Ole N. Mai
Founder of Keupera
The rise of LLMs and AI search has shifted user behavior. 🌸
Instead of classic search, people use ChatGPT, Perplexity, and Google's AI Mode.
To stay relevant, you must measure a new metric: AI Share of Voice (SoV).
1. The Geometry of AI Share of Voice
In Generative Engine Optimization, AI Share of Voice measures the frequency, prominence, and context with which AI systems recommend or cite your brand across a defined universe of industry-specific user prompts.
Unlike regular Google SERPs, where ten links coexist peacefully, AI environments compress thousands of potentially competing options into a tight selection of 3 to 5 recommendations.
If your company fails to cross this conversion filter, your visibility effectively drops to zero.
AI Share of Voice Formular:
AI SoV = ( Σ MentionsBrand × wProminence ) / ( Σ MentionsTotal Category ) × 100
Where the prominence weight (wProminence) scales based on whether your brand is explicitly recommended in the primary text summary, featured alongside a clickable hyperlink citation, or relegated to a background source token. A high raw citation count is meaningless if a competitor consistently captures the primary conversational narrative.
2. Establishing Your Prompt Universe
You cannot measure your visibility everywhere. To compile an accurate baseline, you must construct a structured prompt library that mirrors the actual discovery funnels of real buyers.
Avoid reliance on synthetic or automated prompt generators that fail to match human search behavior. Your tracking universe should be broken into three core operational layers:
Informational / Brand-Agnostic Prompts
These target the top of your marketing funnel. They focus on structural industry questions where an engine must choose which industry entities to cross-reference as examples.
Example: "What are the best frameworks for scaling enterprise cybersecurity infrastructure?"
Commercial / Evaluation Prompts
These directly impact mid-funnel pipeline velocity. Users look to isolate options, request comparison tables, or actively seek structural trade-offs between solutions.
Example: "Compare the top CRM platforms for mid-market logistics companies based on implementation speed."
Transactional / Brand-Specific Prompts
These check your defensive positioning. They verify if AI engines adequately synthesize your documentation, surface true customer sentiment, or accurately understand your specialized feature sets.
Example: "Does [Your Brand] support native zero-trust architecture for local networks?"
3. The Architecture of Manual Tracking (The Blueprint)
For resource-constrained teams or initial audits, building a basic manual testing rig is essential to understand how LLMs interact with your brand's data layers. While manual queries cannot account for prompt volatility, they illustrate the core mechanics of AI extraction.
Establish Clean Sandbox Environments:
LLMs utilize active context windows and user accounts to personalize outputs. When testing, always use unauthenticated API endpoints or completely clean, incognito instances to simulate an unbiased, first-time buyer perspective.
Isolate the Core Citations:
When an engine names your brand, analyze the source. Expand the citation boxes or footnote links. Is the model referencing your owned website, an independent review platform, an unlinked forum thread on Reddit, or a dated industry publication?
Map the Narrative Context:
Visibility can mask reputational damage. Classify the sentiment of the mention into a three-tiered matrix: Positive Recommendation (the AI actively suggests you), Neutral Mentions (you appear passively in a list), or Negative Exclusion (the AI highlights a competitor's advantage over you).
The Micro-Context Framework:
Remember that AI architectures slice web content into isolated text passages. If your brand is listed in an external review article but your core feature set is absent from that paragraph, an LLM will lack the internal semantic connections to surface you during highly specific user queries.
Keupera's AI Brand Radar automates this entire structural mapping, tracking prompt demand and analyzing how optimization adjustments shape multi-engine visibility over time.
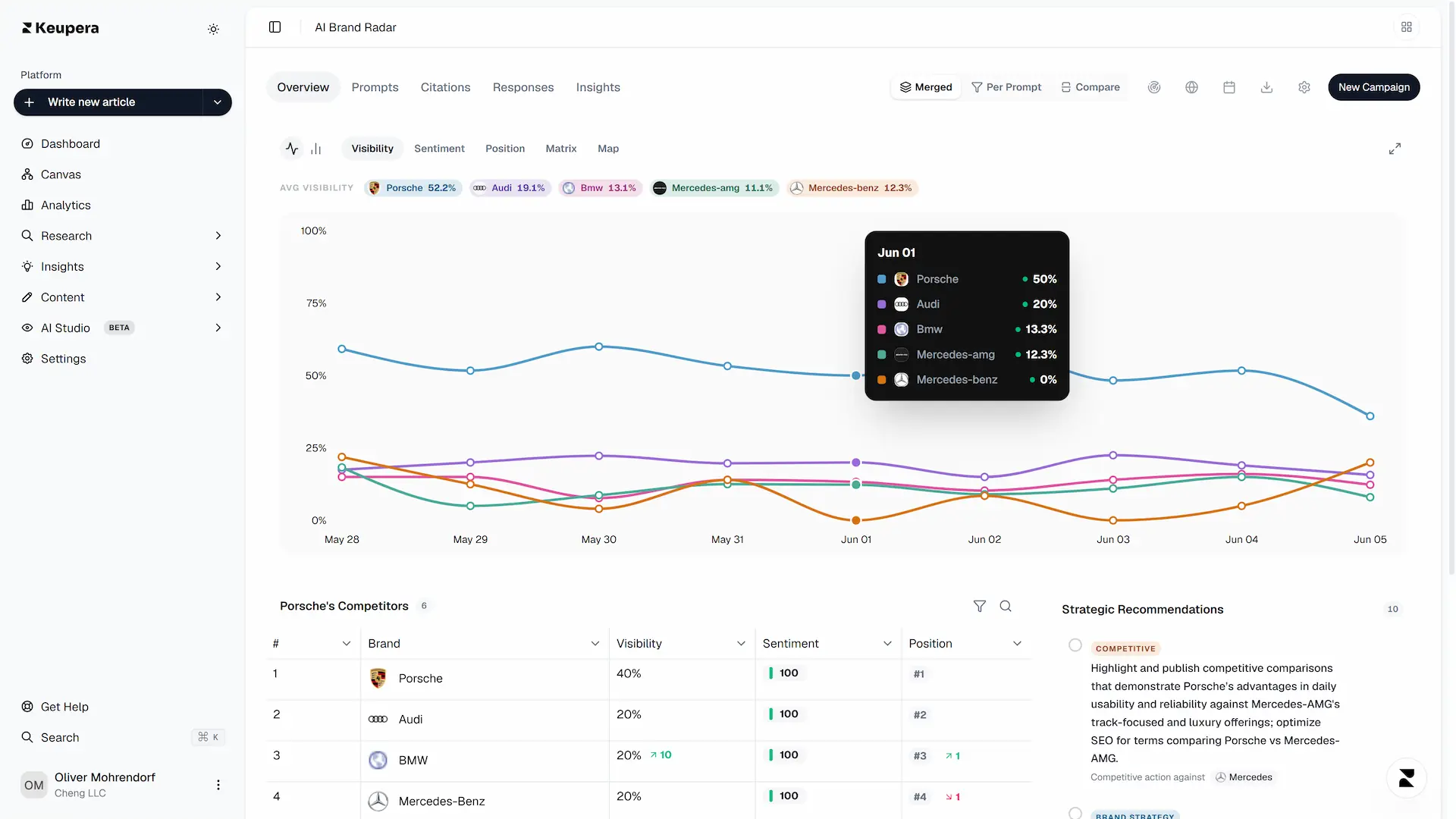
4. Structuring a Unified AI SoV Matrix
To accurately report performance to stakeholders, you must normalize data across completely different engine architectures. For example, Google AI Overviews rely heavily on traditional search indexing and authoritative content blocks, whereas ChatGPT balances conversational training data with live web-browsing execution layers.
The matrix below outlines the exact behavioral variables your tracking strategy must continuously account for:
Engine Family | Primary Score Matrix | Volatility Scale | Core Tracking Metric |
|---|---|---|---|
Google AI Overviews / Mode | Trusted web index | Knowledge Graph, schema-mapped entites | Moderate (tied to core search alrightmic rollouts) |
OpenAI (ChatGPT / Search) | Direct partnership media nodes, live browse queries, pre-trained context | High (frequent system prompt adjustments) | Inline Conversational Recommendation Share |
Perplexity AI | Real-time multi-source web scraping, structured collections. | Extreme (highly dependent on current top-ranking URLs) | Source Index Frequency & Follow-up Prompt Prominence |
5. From Measurement to Optimization (GEO Execution)
Tracking your AI Share of Voice is only useful if it informs your ongoing content generation and authority-building workflows. When a tracking sprint reveals a definitive visibility gap, apply these immediate corrections:
Address Entity Alignment Errors:
If competitors dominate informational queries, check your brand's JSON-LD schema footprint. Use highly explicit Organization, Product, and SameAs properties to structurally bridge your brand to core industry concepts in Wikidata and open directories.
Fix Passages Failing the "Isolate Rule":
Ensure your own pages feature direct, un-fluffy structural answers. If an LLM needs to parse 800 words of background text to locate a simple feature spec, it will bypass your page for a competitor's tightly structured table or bulleted list.
Diversify Off-Page Footprints:
LLMs utilize third-party forums and digital PR nodes to validate claims. If your AI Share of Voice stalls despite flawless on-page optimization, your brand lacks conversational relevance. Prioritize targeted digital PR, engineering review pipelines, and active placement on primary industry source sites.
Want to get more customer from AI search?
Try Keupera's AI Brand Radar today.
More in AI & GEO
Keep reading

AI Search: Why Branded Web Mentions Are the New Backlinks
In AI search, Branded Web Mentions (whether linked or unlinked) are the new backlinks. 🌸 If you want AI models to actively recommend your company, you must master how semantic engines build trust, …

How to Track AI Visibility in 2026
Let’s talk about AI Visibiltiy! 🌸 P eople aren’t just scrolling through a list of blue links anymore. They're opening ChatGPT, Perplexity, or utilizing the newly upgraded AI Mode in Google Search. Wh…
GEO vs SEO vs AI SEO: Key Differences Marketers Need to Know
Search has changed faster in the last two years than it did in the previous ten. If you still treat visibility as a simple race for blue links on Google, you are already behind. Today, brands need to …